My work this week isn’t very interesting, even insomuch as my work any week is interesting, so this week I have elected to start a series of blog posts about the Risch Algorithm in general. I will start out with the basics in this post.
Anyone who has taken Calculus knows a handful of heuristics to calculate integrals. u-substitution, partial fractions, integration by parts, trigonometric substitution, and table integration are a few of the more popular ones. These are general enough to work for most integrals that are encountered in problems in Physics, Engineering, and so on, as well as most of those generated by solving differential equations from the same fields. But these fall short in a couple of ways. First off, they are just heuristics. If they fail, it does not mean that no integral exists. This means that they are useless for proving that certain functions, such as 





The reason that I started with a function and then computed its derivative was to show how easy it is to come up with a very complicated function that has an elementary anti-derivative. Therefore, we see that the methods from calculus are not the ones to use if we want an integration algorithm that is complete. The Risch Integration Algorithm is based on a completely different approach. At its core lies Liouville’s Theorem, which gives us the form of any elementary anti-derivative. (I wish to point out at this point that heuristics like this are still useful in a computer algebra system such as SymPy as fast preprocessors to the full integration algorithm).
The Risch Algorithm works by doing polynomial manipulations on the integrand, which is entirely deterministic (non-heuristic), and gives us the power of all the theorems of algebra, allowing us to actually prove that anti-derivatives cannot exist when they don’t. To start off, we have to look at derivations. As I said, everything with the Risch Algorithm is looked at algebraically (as opposed to analytically). The first thing to look at is the derivative itself. We define a derivation as any function 

1. 
2. 
for any 



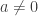




The above definition for the natural logarithm gives the first insight into how the integration algorithm works. We define transcendental functions in terms of their derivatives. So if 

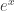



We say that 

1. 
2. ![D[t]\in k[t]](https://s0.wp.com/latex.php?latex=D%5Bt%5D%5Cin+k%5Bt%5D&bg=ffffff&fg=333333&s=0&c=20201002)
The first condition is necessary because the we are only going to deal with the trancenental version of the Risch Algorithm (the algebraic case is solved too, but the solution method is quite different, and I am not implementing it this summer). The second condition just says that the derivative of t is a polynomial in t and a rational function in x. The functions I mentioned above all satisfy these properties for 

![\mathbb{Q}[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BQ%7D%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)








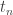




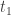


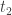






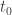


This is the preparsing that I alluded to in an earlier post that I have not implemented yet. The reason that I haven’t implemented it yet is not just because I haven’t gotten around to it. We have to be careful when we build up the extension that each element is indeed transcendental over the already built-up field 

So we can see that we can convert a transcendental integral, such as the one above, into a rational function in x and monomial extensions 





 Posted by Aaron Meurer
Posted by Aaron Meurer  , and you set
, and you set  and
and  (
( and
and  ), then you cannot make
), then you cannot make  because
because  . The ability to determine if an element is a derivative or a logarithmic derivative of an element of the already build differential extension is important not only for building up the extension for the integrand (basically the preparsing), but also for solving some of the cases of the subproblems such as the Risch Differential Equation problem.
. The ability to determine if an element is a derivative or a logarithmic derivative of an element of the already build differential extension is important not only for building up the extension for the integrand (basically the preparsing), but also for solving some of the cases of the subproblems such as the Risch Differential Equation problem. , are indeed so. And I also hope to have some more explanations on how the Risch algorithm works in future posts.
, are indeed so. And I also hope to have some more explanations on how the Risch algorithm works in future posts.  . Also, using
. Also, using  , with
, with  ). Furthermore, we know that the representation of a rational function is not unique. For example,
). Furthermore, we know that the representation of a rational function is not unique. For example,  is the same as
is the same as  except at the point
except at the point  , and
, and  is the same as
is the same as 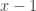 everywhere. But by using
everywhere. But by using 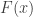 as
as  , where
, where  ,
, 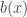 ,
, 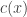 ,
, 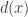 , and
, and  are all polynomials, and the degree of
are all polynomials, and the degree of  is less than the degree of
is less than the degree of  .
.  , where
, where  is a polynomial (note that if
is a polynomial (note that if  , where each
, where each  is square-free (in other words,
is square-free (in other words, 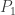 is the product of all the factors of degree 1,
is the product of all the factors of degree 1, 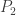 is the product of all the factors of degree 2, and so on). There is a relatively simple algorithm to compute the square-free factorization of a polynomial, which is based on the fact that
is the product of all the factors of degree 2, and so on). There is a relatively simple algorithm to compute the square-free factorization of a polynomial, which is based on the fact that  reduces the power of each irreducible factor by 1. For example:
reduces the power of each irreducible factor by 1. For example:
 , you can obtain
, you can obtain  . Then, by recursively computing
. Then, by recursively computing  ,
,  ,
,  , … and taking the quotient each time as above, we can find the square-free factors of P.
, … and taking the quotient each time as above, we can find the square-free factors of P.  , where
, where 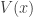 is square-free, the integral will be a rational function if
is square-free, the integral will be a rational function if 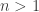 and a logarithm if
and a logarithm if  . We can use the partial fraction decomposition that is easy to find once we have the square-free factorization of the denominator to rewrite the remaining rational function as a sum of terms of the form
. We can use the partial fraction decomposition that is easy to find once we have the square-free factorization of the denominator to rewrite the remaining rational function as a sum of terms of the form  , where
, where  is square-free. Because
is square-free. Because  is square-free,
is square-free,  , so the
, so the 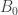 and
and 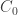 such that
such that  (recall that
(recall that  is the gcd of
is the gcd of  and
and  if and only if there exist
if and only if there exist  relatively prime to
relatively prime to  . This holds true for integers as well as polynomials). Thus we can find
. This holds true for integers as well as polynomials). Thus we can find  and
and  such that
such that  . Multiplying through by
. Multiplying through by  ,
,  , which is equal to
, which is equal to  . You may notice that the term in the parenthesis is just the derivative of
. You may notice that the term in the parenthesis is just the derivative of  , so we get
, so we get  . This is called Hermite Reduction. We can recursively reduce the integral on the right hand side until the
. This is called Hermite Reduction. We can recursively reduce the integral on the right hand side until the 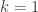 . Note that there are more efficient ways of doing this that do not actually require us to compute the partial fraction decomposition, and there is also a linear version due to Mack (this one is quadratic), and an even more efficient algorithm called the Horowitz-Ostrogradsky Algorithm, that doesn’t even require a square-free decomposition.
. Note that there are more efficient ways of doing this that do not actually require us to compute the partial fraction decomposition, and there is also a linear version due to Mack (this one is quadratic), and an even more efficient algorithm called the Horowitz-Ostrogradsky Algorithm, that doesn’t even require a square-free decomposition.  , where
, where  and
and  are monic polynomials split into linear factors. Clearly, the resultant of two polynomials is 0 if and only if the two polynomials share a root. It is an important result that the resultant of two polynomials can be computed from only their coefficients by taking the determinant of the
are monic polynomials split into linear factors. Clearly, the resultant of two polynomials is 0 if and only if the two polynomials share a root. It is an important result that the resultant of two polynomials can be computed from only their coefficients by taking the determinant of the 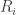 is multiplied by a constant
is multiplied by a constant 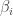 . The Fundamental PRS Theorem shows how to compute specific
. The Fundamental PRS Theorem shows how to compute specific  , left over from the Hermite Reduction (so
, left over from the Hermite Reduction (so  , where
, where 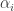 be the distinct roots of R. Let
be the distinct roots of R. Let  . Then it turns out that the logarithmic part of the integral is just
. Then it turns out that the logarithmic part of the integral is just  . This is called the Rothstein-Trager Algorithm.
. This is called the Rothstein-Trager Algorithm. will appear in the PRS of
will appear in the PRS of  . Furthermore, we can use the PRS to immediately find the resultant
. Furthermore, we can use the PRS to immediately find the resultant 


