Just a few moments ago, a branch was pushed in that fixed one of my biggest grievances in SymPy, if not the biggest. Previously we had this behavior:
In [1]: sqrt(x) Out[1]: x**(1/2) In [2]: solve(x**2 - 2, x) Out[2]: [-2**(1/2), 2**(1/2)]
Now suppose you took the output of those expressions and pasted them into isympy:
In [3]: x**(1/2) Out[3]: x**0.5 In [4]: [-2**(1/2), 2**(1/2)] Out[4]: [-1.41421356237, 1.41421356237]
That’s with __future__.division. Here’s what would happen with old division:
In [2]: x**(1/2) Out[2]: 1 In [3]: [-2**(1/2), 2**(1/2)] Out[3]: [-1, 1]
This is because with old division, 1/2 evaluates to 0.
The problem is that Python evaluates 1/2 to 0.5 (or 0) before SymPy has a change to convert it to a Rational. There were several ways that people got around this. If you copy an expression with number division in it and want to paste it into a SymPy session, the easiest way to do this was to pass it as a string to sympify():
In [1]: sympify("x**(1/2)")
Out[1]: x**(1/2)
In [2]: sympify("[-2**(1/2), 2**(1/2)]")
Out[2]: [-2**(1/2), 2**(1/2)]
If that was too much typing for you, you could use the S() shortcut to sympify()
In [3]: S("x**(1/2)")
Out[3]: x**(1/2)
In [4]: S("[-2**(1/2), 2**(1/2)]")
Out[4]: [-2**(1/2), 2**(1/2)]
This solution is fine if you want to paste an expression into a SymPy session, but it’s not a very clean one if you want to paste code into a script. For that, you need to modify the code so that it no longer contains Python int/Python int. The easiest way to do this is to sympify one of the ints. So you would do something like
In [5]: x**(S(1)/2) Out[5]: x**(1/2) In [6]: [-2**(S(1)/2), 2**(S(1)/2)] Out[6]: [-2**(1/2), 2**(1/2)]
This wasn’t terribly readable, though. The best way to fix the problem when you had a power of one half was to use sqrt(), which is a shortcut to Pow(…, Rational(1, 2)).
Well, this last item should make you think. If sqrt(x) is more readable than x**(S(1)/2) or even x**(1/2), why not print it like that in the first place. Well, I thought so, so I changed the string printer, and now this is the way that SymPy works. So 90% of the time, you can just paste the result of str() or print, and it will just work, because there won’t be any **(1/2), which was by far the most common problem of “Python evaluating the expression to something before we can.” In the git master, SymPy now behaves like
In [1]: sqrt(x) Out[1]: sqrt(x) In [2]: solve(x**2 - 2, x) Out[2]: [-sqrt(2), sqrt(2)]
You can obviously just copy and paste these results, and you get the exact same thing back. Not only does this make expressions more copy-and-pastable, but the output is much nicer in terms of readability. Here are some before and afters that come from actual SymPy doctests that I had to change after fixing the printer:
Before: >>> e = ((2+2*sqrt(2))*x+(2+sqrt(8))*y)/(2+sqrt(2)) >>> radsimp(e) 2**(1/2)*x + 2**(1/2)*y After: >>> radsimp(e) sqrt(2)*x + sqrt(2)*y
Before: >>> b = besselj(n, z) >>> b.rewrite(jn) 2**(1/2)*z**(1/2)*jn(n - 1/2, z)/pi**(1/2) After: >>> b.rewrite(jn) sqrt(2)*sqrt(z)*jn(n - 1/2, z)/sqrt(pi)
Before:
>>> x = sympify('-1/(-3/2+(1/2)*sqrt(5))*sqrt(3/2-1/2*sqrt(5))')
>>> x
(3/2 - 5**(1/2)/2)**(-1/2)
After
>>> x
1/sqrt(3/2 - sqrt(5)/2)
And not only is sqrt(x) easier to read than x**(1/2) but it’s fewer characters.
In the course of changing this, I went ahead and did some greps of the repository to get rid of all **(S(1)/2), **Rational(1, 2) and similar throughout the code base (not just in the output of doctests where the change had to be made), replacing them with just sqrt. Big thanks to Chris Smith for helping me catch all instances of this. Now the code should be a little easier to read and maintain.
Future Work
This is a big change, and I believe it will fix the copy-paste problem for 90% of expressions. But it does not solve it completely. It is still possible to get int/int in the string form of an expression. Only powers of 1/2 and -1/2 are converted to sqrt, so any other rational power will still print as a/b, like
In [1]: x**Rational(3, 2) Out[1]: x**(3/2)
Also, as you may have noticed in the last example above, a rational number that sits by itself will still be printed as int/int, like
In [2]: (1 + x)/2 Out[2]: x/2 + 1/2
Therefore, I’m leaving the issue for this open to discuss potential future fixes to the string printer. One idea is to create a root function that is a shortcut to root(x, a) == x**(1/a). This would work for rational powers where the numerator is 1. For other rational powers, we could then denest these with an integer power. It’s important to do this in the right order, though, as they are not equivalent. You can see that SymPy auto-simplifies it when it is mathematically correct in all cases, and not when it is not:
In [3]: sqrt(x**3) Out[3]: sqrt(x**3) In [4]: sqrt(x)**3 Out[4]: x**(3/2)
Thus 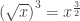
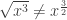

So the idea would be to print Pow(expr, Rational(a, b)) as root(expr, b)**a.
The merits of this are debatable, but anyway I think we should have this root() function in any case (see issue 2643).
Another idea, which is probably not a good one, is to always print int/int as S(int)/int. So we would get
>>> Rational(1, 2) S(1)/2 >>> x**Rational(4, 5) x**(S(4)/5)
This is probably a bad idea because even though expressions would always be copy-pastable, they would be slightly less readable.
By the way, in case you didn’t catch it, all of these changes only affect the string printer. The pretty printer remained unaffected, and would under any additional changes, as it isn’t copy-pastable anyway, and already does a superb job of printing roots.



 Posted by Aaron Meurer
Posted by Aaron Meurer 


