Cross posted on the official SymPy Blog
SymPy 0.7.1 has been released on July 29, 2011. It is available at
The source distribution can be downloaded from:
http://code.google.com/p/sympy/downloads/detail?name=sympy-0.7.1.tar.gz
You can get the Windows installer here:
http://code.google.com/p/sympy/downloads/detail?name=sympy-0.7.1.win32.exe
And the html documentation here:
http://code.google.com/p/sympy/downloads/detail?name=sympy-0.7.1-docs-html.zip
About SymPy
SymPy is a Python library for symbolic mathematics. It aims to become a full-featured computer algebra system (CAS) while keeping the code as simple as possible in order to be comprehensible and easily extensible. SymPy is written entirely in Python.
Release notes
Major changes
– Python 2.4 is no longer supported. SymPy will not work at all in
Python 2.4. If you still need to use SymPy under Python 2.4 for some
reason, you will need to use SymPy 0.7.0 or earlier.
– The Pyglet plotting library is now an (optional) external dependency.
Previously, we shipped a version of Pyglet with SymPy, but this was
old and buggy. The plan is to eventually make the plotting in SymPy
much more modular, so that it supports many backends, but this has not
been done yet. For now, still only Pyglet is directly supported.
Note that Pyglet is only an optional dependency and is only needed for
plotting. The rest of SymPy can still be used without any dependencies
(except for Python).
– isympy now works with the new IPython 0.11.
– mpmath has been updated to 0.17. See the corresponding mpmath release
notes at http://mpmath.googlecode.com/svn/trunk/CHANGES.
– Added a Subs object for representing unevaluated substitutions. This
finally lets us represent derivatives evaluated at a point, i.e.,
`diff(f(x), x).subs(x, 0)` returns `Subs(Derivative(f(_x), _x), (_x,), (0,))`.
This also means that SymPy can now correctly compute the chain rule
when this functionality is required, such as with `f(g(x)).diff(x)`.
Hypergeometric functions/Meijer G-Functions
– Added classes hyper() and meijerg() to represent Hypergeometric and Meijer G-functions, respectively. They support numerical evaluation (using mpmath) and symbolic differentiation (not with respect to the parameters).
– Added an algorithm for rewriting hypergeometric and meijer g-functions in terms of more familiar, named special functions. It is accessible via the function hyperexpand(), or also via expand_func(). This algorithm recognises many elementary functions, and also complete and incomplete gamma functions, bessel functions, and error functions. It can easily be extended to handle more classes of special functions.
Sets
– Added FiniteSet class to mimic python set behavior while also interacting with existing Intervals and Unions
– FiniteSets and Intervals interact so that, for example `Interval(0, 10) – FiniteSet(0, 5)` produces `(0, 5) U (5, 10]`
– FiniteSets also handle non-numerical objects so the following is possible `{1, 2, ‘one’, ‘two’, {a, b}}`
– Added ProductSet to handle Cartesian products of sets
– Create using the `*` operator, i.e. `twodice = FiniteSet(1, 2, 3, 4, 5, 6) * FiniteSet(1, 2, 3, 4, 5, 6) or square = Interval(0, 1) * Interval(0, 1)`
– pow operator also works as expected: `R3 = Interval(-oo, oo)**3 ; (3, -5, 0) in R3 == True`
– Subtraction, union, measurement all work taking complex intersections into account.
– Added as_relational method to sets, producing boolean statements using And, Or, Eq, Lt, Gt, etc…
– Changed reduce_poly_inequalities to return unions of sets rather than lists of sets
Iterables
– Added generating routines for integer partitions and binary partitions. The routine for integer partitions takes 3 arguments, the number itself, the maximum possible element allowed in the partitions generated and the maximum possible number of elements that will be in the partition. Binary partitions are characterized by containing only powers of two.
– Added generating routine for multi-set partitions. Given a multiset, the algorithm implemented will generate all possible partitions of that multi-set.
– Added generating routines for bell permutations, derangements, and involutions. A bell permutation is one in which the cycles that compose it consist of integers in a decreasing order. A derangement is a permutation such that the ith element is not at the ith position. An involution is a permutation that when multiplied by itself gives the identity permutation.
– Added generating routine for unrestricted necklaces. An unrestricted necklace is an a-ary string of n characters, each of a possible types. These have been characterized by the parameters n and k in the routine.
– Added generating routine for oriented forests. This is an implementation of algorithm S in TAOCP Vol 4A.
xyz Spin bases
– The represent, rewrite and InnerProduct logic has been improved to work between any two spin bases. This was done by utilizing the Wigner-D matrix, implemented in the WignerD class, in defining the changes between the various bases. Representing a state, i.e. `represent(JzKet(1,0), basis=Jx)`, can be used to give the vector representation of any get in any of the x/y/z bases for numerical values of j and m in the spin eigenstate. Similarly, rewriting states into different bases, i.e. `JzKet(1,0).rewrite(‘Jx’)`, will write the states as a linear combination of elements of the given basis. Because this relies on the represent function, this only works for numerical j and m values. The inner product of two eigenstates in different bases can be evaluated, i.e. `InnerProduct(JzKet(1,0),JxKet(1,1))`. When two different bases are used, one state is rewritten into the other basis, so this requires numerical values of j and m, but innerproducts of states in the same basis can still be done symbolically.
– The `Rotation.D` and `Rotation.d` methods, representing the Wigner-D function and the Wigner small-d function, return an instance of the WignerD class, which can be evaluated with the `doit()` method to give the corresponding matrix element of the Wigner-D matrix.
Other changes
– We now use MathJax in our docs. MathJax renders LaTeX math entierly in
the browser using Javascript. This means that the math is much more
readable than the previous png math, which uses images. MathJax is
only supported on modern browsers, so LaTeX math in the docs may not
work on older browsers.
– nroots() now lets you set the precision of computations
– Added support for gmpy and mpmath’s types to sympify()
– Fix some bugs with lambdify()
– Fix a bug with as_independent and non-commutative symbols.
– Fix a bug with collect (issue 2516)
– Many fixes relating to porting SymPy to Python 3. Thanks to our GSoC
student Vladimir Perić, this task is almost completed.
– Some people were retroactively added to the AUTHORS file.
– Added a solver for a special case of the Riccati equation in the ODE
module.
– Iterated derivatives are pretty printed in a concise way.
– Fix a bug with integrating functions with multiple DiracDeltas.
– Add support for Matrix.norm() that works for Matrices (not just vectors).
– Improvements to the Groebner bases algorithm.
– Plot.saveimage now supports a StringIO outfile
– Expr.as_ordered_terms now supports non lex orderings.
– diff now canonicalizes the order of differentiation symbols. This is
so it can simplify expressions like `f(x, y).diff(x, y) – f(x,
y).diff(y, x)`. If you want to create a Derivative object without
sorting the args, you should create it explicitly with `Derivative`,
so that you will get `Derivative(f(x, y), x, y) != Derivative(f(x, y), y, x)`.
Note that internally, derivatives that can be computed are always
computed in the order that they are given in.
– Added functions `is_sequence()` and `iterable()` for determining if
something is an ordered iterable or normal iterable, respectively.
– Enabled an option in Sphinx that adds a `source` link next to each function, which links to a copy of the source code for that function.
In addition to the more noticeable changes listed above, there have been numerous other smaller additions, improvements and bug fixes in the ~300 commits in this release. See the git log for a full list of all changes. The command `git log sympy-0.7.0..sympy-0.7.1` will show all commits made between this release and the last. You can also see the issues closed since the last release [here](http://code.google.com/p/sympy/issues/list?can=1&q=closed-after%3A2010%2F6%2F13+closed-before%3A2011%2F7%2F30&sort=-closed&colspec=ID+Type+Status+Priority+Milestone+Owner+Summary+Stars+Closed&cells=tiles).
Authors
The following people contributed at least one patch to this release (names are given in alphabetical order by last name). A total of 26 people contributed to this release. People with a * by their names contributed a patch for the first time for this release. Five people contributed for the first time for this release.
Thanks to everyone who contributed to this release!
* Tom Bachmann
* Ondřej Čertík
* Renato Coutinho
* Bill Flynn
* Bradley Froehle*
* Gilbert Gede
* Brian Granger
* Emma Hogan*
* Yuri Karadzhov
* Stefan Krastanov*
* Ronan Lamy
* Tomo Lazovich
* Sam Magura*
* Saptarshi Mandal
* Aaron Meurer
* Sherjil Ozair
* Mateusz Paprocki
* Vladimir Perić
* Mario Pernici
* Nicolas Pourcelot
* Min Ragan-Kelley*
* Matthew Rocklin
* Chris Smith
* Vinzent Steinberg
* Sean Vig
* Thomas Wiecki



 Posted by Aaron Meurer
Posted by Aaron Meurer 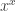 to be rewritten as
to be rewritten as  before it can integrate them, but I try to convert them back after integrating so that the user gets the same thing in the result that he entered. I created
before it can integrate them, but I try to convert them back after integrating so that the user gets the same thing in the result that he entered. I created 
