This blog has moved to http://asmeurer.github.io/
See http://asmeurer.github.io/blog/posts/moving-to-github-pages-with-nikola/ for more details on why I have moved. For now, all posts on this blog have not been migrated.
This blog has moved to http://asmeurer.github.io/
See http://asmeurer.github.io/blog/posts/moving-to-github-pages-with-nikola/ for more details on why I have moved. For now, all posts on this blog have not been migrated.
 Leave a Comment » |
Leave a Comment » |  Uncategorized |
Uncategorized |  Permalink
Permalink
 Posted by Aaron Meurer
Posted by Aaron Meurer
In my previous post about switching to Python 3 as my default Python, I praised the use of a single codebase for supporting both Python 2 and Python 3. I even chastised the Python core developers for creating 2to3, writing, “I think that the core Python folks made a mistake by presenting Python 3 as a new language. It has made people antagonistic against Python 3 (well, that and the print function, which was another stupid mistake, because even if it was a good idea, it alone has kept too many people from switching). 2to3 was a mistake too, because it perpetuated this idea.”
Well, this isn’t entirely fair, because I myself used to be one of the biggest advocates of using 2to3 over a single codebase. Take this GitHub comment from when the IPython guys were considering this issue, where I wrote, “maintaining a common code base is going to be a bit annoying from the developer side.…The main benefit of using 2to3 is that 99% of the time, you can just write your code as you would for Python 2, and when it gets to Python 3, it just works (maybe that percent is a bit smaller if you use strings a lot, but it’s still quite high). To write for Python 2 and 3 at the same time, you have to remember a lot of little rules, which no one will remember (and new contributors will not even know about). And given that IPython’s test coverage is still poor (unless I am mistaken, in which case, please correct me), little mistakes will slip through, and no one will notice until they try the certain behavior in Python 3.”
So I just want to clarify a few things.
from __future__ import print_function was introduced in Python 2.6. This means that to support a single codebase for 2.5-3.x you have to write print('\n') to print an empty line and to print something without a newline at the end, you have to use sys.stdout.write. Also, except Exception as e, using the as keyword, which is the only syntax allowed in Python 3, was introduced in Python 2.6, so if you want to catch an exception you have to use sys.exc_info()[1]. Now that really is annoying. But in Python 2.6, most differences can be fixed with simple definitions, most of which boil down to try, except ImportError, import x as y type workarounds. The worst are the print function, which can be imported from __future__, division, which can also be imported from __future__ (or worked around), and unicode literals (if it’s a big deal, drop support for Python 3.2). Most other things are just simple renames, like xrange -> range, or making sure that you wrap functions that are iterators in Python 3 in list if you want to access items from them.map(f, s)[0] doesn’t work in Python 3 or that the StringIO module has been renamed to io, or that you can’t pass around data as strings—they have to be bytes.
Of course, you also need good test coverage to support Python 3 well using 2to3, but you can get away with more because 2to3 will take care of things like the above for you. Perhaps instead of 2to3 what really should have been made is a pyflakes-like tool that uses the same knowledge as 2to3 to check for cross-compatibility for Python 2 and Python 3.
With the single codebase, your view should change. You should start prototyping in Python 3. You should only use Python 2 to test that things work in Python 2 (and since you’ve been using Python 2 for so long before switching to Python 3, or at least if you’re like me you have, this is not that bad). Just yesterday, I found a bug in SymPy in Python 3 that went unnoticed. It relates to what I said above about using bytes instead of strings for data. I just checked, and 2to3 wouldn’t have fixed it (and indeed, the bug is present in SymPy 0.7.3, which used 2to3), because there’s no way for 2to3 to have known that the data was bytes and not a string. The code was obviously untested, but it would have been obvious that it didn’t work if anyone was using Python 3 to use SymPy interactively. As it turns out, some of our users are doing this, and they pointed it out on the mailing list, but it remained unfixed until I found it myself independently.
So old mistakes aside, the lessons to take away from this and the previous blog post are
Leave a Comment » | Uncategorized | Permalink
Posted by Aaron Meurer
So I just finished my internship with Continuum. For the internship, I primarily worked on Anaconda, their free Python distribution, and conda, its free (BSD open source) package manager. I might write a blog post about conda later, but suffice it to say that I’m convinced that it is doing package management the right way. One of the major developments this summer that I helped out with was the ability for anybody to build a conda package, and a site called Binstar where people can upload them (the beta code is “binstar in beta” with no quotes).
Another thing that happened over the summer is that Almar Klein made conda Python 3 compatible, so that it can be used with the Pyzo project, which is Python 3 only. The way this was done was by using a single code base for Python 2 and Python 3. Thus, this became the first time I have done any heavy development on Python source that had to be Python 3 compatible from a single codebase (as opposed to using the 2to3 tool).
Another development this summer was that SymPy was released (0.7.3). This marked the last release to support Python 2.5. Around the same time, we discussed our Python 3 situation, and how annoying it is to run use2to3 all the time. The result was this pull request, which made SymPy use a single code base for Python 2 and Python 3. Now, that pull request is hard to mull through, but the important part to look at is the compatibility file. Everything in that file has to be imported and used, because it represents things that are different between Python 2 and Python 3. Ondřej has written more about this on his blog.
In all, I think that supporting Python 2.6-3.3 (not including 3.0 or 3.1) is not that bad. The compatibility file has a few things, but thinking back, it was just that bad or worse supporting Python 2.4-2.7 (heck, back then, we couldn’t even use the all function without importing it). The situation is much better today now that we use Travis too, since any mistake is caught before the pull request is merged. The worst of course is the print function, but since that can be imported from __future__, I will be warned about it pretty fast, since print as a statement is a SyntaxError in that case. It also doesn’t take that long to get into the habit of typing () after print.
Of course, there are a lot of nice Python 3 only features that we cannot use, but this was the case for supporting Python 2.4-2.7 too (e.g., the with statement and the ternary statement were both introduced in Python 2.5). So this is really nothing new. There is always a stick to drop the oldest Python version we support, and a lag on what features we can use. Now that we have dropped Python 2.5 support in SymPy, we can finally start using new-style string formatting, abstract base classes, relative imports, and keyword arguments after *args.
So as a result of this, I’ve come to the conclusion that Python 3 is not another language. It’s just another version of the same language. Supporting Python 2.6-3.3 is no different from supporting Python 2.4-2.7. You have to have some compatibility imports, you can’t use new language features, and you have to have good test coverage. I think that the core Python folks made a mistake by presenting Python 3 as a new language. It has made people antagonistic against Python 3 (well, that and the print function, which was another stupid mistake, because even if it was a good idea, it alone has kept too many people from switching). 2to3 was a mistake too, because it perpetuated this idea.
In the past, I have always developed against the latest version of Python: 2.6 was the best when I learned Python, and then 2.7. Even though I have had to support back to 2.4, I only used 2.4 explicitly when testing.
Well, given what I said above, the only logical thing to do is to use Python 3.3 as my main development Python. If you use Anaconda, there are basically two ways you can do this. The first is to just create a Python 3 environment (conda create -n python3 python=3), and put that first in your PATH (you also will need to add source activate python3 to your bash profile if you go this route, so that conda install will install into that environment by default). For me, though, I plan to use a Python 3 version of Anaconda, which has Python 3 as the default. The main difference here is that conda itself is written in Python 3. Aside from purity, and the fact that I plan to fix any occasional conda bugs that I come across, the other difference here is that conda itself will default to Python 3 in this case (i.e., when creating a new environment with Python like conda create -n envname python, the Python will be Python 3, not Python 2, and also it will build against Python 3 by default with conda build). Continuum does not yet make Python 3 versions of Anaconda, but there are Python 3 versions of Miniconda (Miniconda3), which is a stripped down version of Anaconda with just Python, the conda package manager, and its dependencies. You can easily install Anaconda into it though with conda install anaconda. I personally prefer to install only what I need to keep the disk usage low (on an SSD, disk space is sparse), so this is perfect for me anyway.
My recommendation is to put a Python 2 installation second in your PATH, so that you can easily call python2 if you want to use Python 2. The easiest way to do this is to create a conda environment for it (conda create -n python2 python=2) and add ~/anaconda/envs/python2 to your PATH.
So far, I have run into a few issues:
ipython entry point into Python 3 environments. Even so, one has to remember this when installing old versions of IPython in environments. setup.py develop against anything that uses 2to3 (like IPython). source activate python2 when I am using Python 2. Or, for a one-off, I can just use python2, and keep a Python 2 environment second in my PATH. But this issue is not really new. For example, really old versions of SymPy only work with Python 2.5, because they used as as a variable name./usr/bin/env python3 in the shebang line. But for SymPy, I have to be aware of how to support 2.6-3.3, so I have to know all the features that are only in some versions anyway. On the other side of things, if I run some random Python script with a shebang line, it probably is going to expect Python 2 and not Python 3, so I either have to explicitly add python2 to the command or activate a Python 2 environmentprint as a statement instead of a function, so I either have to fix it manually before pasting it or use Python 2. I had tried at one point to make a %print magic for IPython that would let print work like a statement in Python 3, but I never finished it. I guess I should revisit it.I’ll update this list as I come across more issues.
In all, so far, it’s nothing too bad. Conda makes switching back to Python 2 easy enough, and dealing with these issues are hardly the worst thing I have to deal with when developing with Python. And if anything, seeing Python 2-3 bugs and issues makes me more aware of the differences between the two versions of the language, which is a good things since I have to develop against code that has to support both.
5 Comments | Uncategorized | Permalink
Posted by Aaron Meurer
So I have just published SymPy 0.7.3.rc1. I’ll write a blog post about the release itself when we release 0.7.3 final, but for now, I wanted to write about how we managed to automate our release process.
Our story begins back in October of 2012, when I wrote a long winded rant to the mailing list about how long it was taking to get the 0.7.2 release out (it took over a month from the time the release branch was created).
The rant is fun, and I recommend reading it. Here are some quotes
The intro:
Now here’s a timeline: 0.7.1 was released July 29, 2011, more than a year and two months ago. 0.7.0 was released just over a month before that, on June 28. 0.6.7 was released March 18, 2010, again over a year before 0.7.0. In almost two year’s time, we’ve had three releases, and are struggling to get out a fourth. And it’s not like there were no changes; quite the opposite in fact. If you look at SymPy 0.6.6 compared to the current master, it’s unbelievable the amount of changes that have gone forward in that time. We’ve had
since then the new polys, at least four completely new submodules (combinatorics, sets, differential geometry, and stats), massive improvements to integration and special functions, a ton of new stuff in the physics module, literally thousands of bug fixes, and the list goes on. Each of these changes on it’s own was enough to warrant a release.So in case I didn’t make my point, le me state it explicitly: we need to release more often. We need to release *way* more often.
My views on some of the fundamental (non-technical) issues:
I think that one other thing that has held back many releases is the feeling of “wait, we should put this in the release”. The use of a release branch has helped keep master moving along independently, but there still seems to be the feeling with many branches of, “this is a nice feature, it ought to go in the release.” My hope is that by making the release process smoother, we can release more often, and this feeling will go away, because it won’t be a big deal if something waits until the next release. As far as deprecations go, the real issue with them is time, not release numbers. So if we deprecate a feature today vs. one month from today, it’s not a big deal (as opposed to today vs. a year from today), regardless of how many versions are in between.
I read about what GitHub does for their Windows product regarding releasing often on their blog: https://github.com/blog/1271-how-we-ship-github-for-windows (they actually have this philosophy for all their products). One thing that they said is, “And by shipping updates so often, there is less anxiety about getting a particular feature ready for a particular release. If your pull request isn’t ready to be merged in time for today’s release, relax. There will be another one soon, so make that code shine!” I think that is exactly the point here. Another thing that they noted is that automation is the key to doing this, which is what I am aiming for with the above point.
My vision:
Once we start releasing very often (and believe me, this is way down the road, but I’m trying to be forward looking here), we can do away with release candidates. A release candidate lives in the wild for a week before the full release. But if we are capable of releasing literally every week, then having release candidates is pointless. If a bug slips into a release, we just fix it and it will be in the next release.
…
We should release *at least* once a month. I think that if the process is automated enough, that this will be very possible (as opposed to the current situation, where the release branch lasts longer than a month). In times of high activity, we can release more often than that (e.g., after a big pull request is merged, we can release).
That was October. Today is July. Basically, our release process was way too long. Half of it was testing stuff, half of it was tedious releasing stuff (like making tarballs and so on), and half of it was updating websites.
We have moved all our testing to Travis CI. So now every pull request is tested, and we can be pretty much assured that master is always passing the tests. There is still some work to do here (currently Travis CI doesn’t test with external dependencies), but it’s mostly a solved problem.
For updating websites, we conceded that we are not going to update anything that we don’t own. That means no attempting to make Debian or Sage packages, or updating Wikipedia or Freshmeat. Someone else will do that (and does anyone even use Freshmeat any more?).
That leaves the releasing itself. It’s still a pain, because we have to make a source tarball, Windows installer, html docs, and pdf docs, and do them all for both Python 2 and Python 3.
So Ondrej suggested moving to fabric/vagrant. At the SciPy 2013 sprints, he started working on a fabfile that automates the whole process. Basically vagrant is a predefined Linux virtual machine that makes it easy to make everything completely reproducible. Fabric is a tool that makes it easy to write commands (in Python) that are run on that machine.
Building the basic stuff was easy, but I want to automate everything. So far, not everything is done yet, but we’re getting close. For example, in addition to building the tarballs, the fabric script checks the contents of the tarball against git ls-files to make sure that nothing is included that shouldn’t be or left out accidentally (and, indeed, we caught some missing files that weren’t included in the tarball, including the README).
You can run all this yourself. Checkout the 0.7.3 branch from SymPy, then cd into the release directory, and read the README. Basically, you just install Fabric and Vagrant if you don’t have them already, then run
vagrant up fab vagrant prepare fab vagrant release
Note that this downloads a 280 MB virtual machine, so it will take some time to run for the first time. When you do this, the releases are in the `release` directory.
Finally, I uploaded 0.7.3.rc1 to GitHub using the new releases feature. This is what the release looks like on GitHub, from the user point of view

This is what it looks like to me

GitHub has (obviously) the best interface I’ve ever seen for this. Of course, even better would be if there were an API, so that I could automate this too. But since Google’s announcement that they are discontinuing downloads, we can no longer upload to Google Code. Our plan was to just use PyPI, but I am glad that we can have at least one other location, especially since PyPI is so buggy and unreliable (I can’t even log in, I get a 502).
So please download this release candidate and test it. We espeically need people to test the Windows installer, since we haven’t automated that part yet (actually, we are considering not making them any more, especailly given the existence of people like Christoph Gohlke who make them for SymPy anyway, but we’ll see). The only thing that remains to be done is to finish writing the release notes. If you made any contributions to SymPy since the last release, please add them there. Or if you want to help out, you can go through our pull requests and make sure that nothing is missing.
2 Comments | Uncategorized | Permalink
Posted by Aaron Meurer
This past week was the 2013 SciPy conference. It was an exciting time, and a lot of interesting things happened.
First, a background. This summer, I have been doing an internship with Continuum Analytics. There I have been working mainly on Anaconda and conda. Anaconda is Continuum’s free (to everyone) Python distribution, which makes it really easy to get bootstrapped with all the scientific software (including SymPy). Conda is Anaconda’s package manager, which, I think, solves many if not all of the main issues with the Python packaging tools like pip, easy_install, PyPI, and virtualenv.
I may write more about that later, but for now, I want to write about my experiences at the conference. The main point there is that I have already been in Austin for about a month, so getting to the conference this year was pretty easy.
On the first day of the conference, on Monday morning, Ondrej Certik and I had our tutorial for SymPy. For the past couple of months, I have been rewriting the official SymPy tutorial from scratch. The official tutorial for SymPy was very old, and had many issues. It only went over features that were good at the time of its writing, so while nothing in the tutorial was wrong, it didn’t really represent the latest and greatest of the library. Also, it was written just like a list of examples, which is not much more than the API docs. In my new tutorial, I aimed to give a narrative style documentation, which starts from the very beginning of what symbolics are and works its way up to the basic functionality of things like solving and simplifying expressions. My goal was also to lead by example, and in particular, to avoid teaching things that I think either are antipatterns, or lead to antipatterns. In Python, there is one– and preferably only one –way to do it. In SymPy, by the nature of the library, there are about seven different ways to create a Symbol, for example (see https://github.com/sympy/sympy/wiki/Idioms-and-Antipatterns, the section, “Creating Symbols”). But there is one best way to do it: by using symbols(). So all throughout the tutorial, I just use symbols(), even if I am creating a single Symbol. I avoid messy things like var.
The final tutorial is at http://docs.sympy.org/tutorial/tutorial/. This was the basis for the tutorial that Ondrej and I gave at SciPy. The site for our tutorial is at http://certik.github.io/scipy-2013-tutorial/html/index.html. There are links to videos, slides, and exercise notebooks there.
I think our tutorial was a great success. People liked (I think) the introduction from nothing to SymPy. For our exercises, we used the IPython Doctester. I think that people really liked this way of doing exercises, but there were some issues getting it to work on everyone’s machine.
In addition to my stuff, Ondrej presented some notebooks of examples of work that he has used in his work at LANL. I think this worked well. There were several physicists in the audience, who understood most of the content, but even for those who weren’t (including me!), it really showed that SymPy is a useful tool. In a beginner tutorial, it is easy to get lost in the easy details, and forget that in the end, you can actually use SymPy to compute some powerful things. SymPy has in the past year or two really passed the barrier of toy to tool.
After our tutorial, I attended the IPython tutorial, and the two-part Scikit-Learn tutorial. The most awesome part of this was just getting to meet people. Fernando Perez, Thomas Kluyver, and Brian Granger of IPython were at the conference. Brain is also a SymPy developer, who has spearheaded the quantum module. From SymPy, in addition to Ondrej (who created SymPy), I met Matthew Rocklin, one of the top contributors, Jason Moore, one of the developers of PyDy, which uses SymPy’s mechanics module, and David Li, who works on SymPy Gamma and SymPy Live (more on these people later).
After the tutorials, Wednesday and Thursday were the talks. There were a lot of good ones. Here are the ones that I remember the most
Topping off the week were the sprints on Friday and Saturday. My goal was to get out a release of SymPy. We didn’t quite get that far, but we got close. We are only blocking on a few small things to get out a release candidate, so expect one before the end of the week. We did introduce a lot of people to SymPy at the sprints, though, and got some first time contributions. Definitely I think we made a lot more people aware of SymPy at this conference than we ever have before.
Another interesting thing at the sprints: before the conference, I was telling David Li that we should switch to Dill for SymPy Live (the way SymPy Live works on the App Engine, it has to pickle the session between runs, because there is a 60 time limit on each execution). Dill is a library that extends Python’s pickle so that it can pickle just about anything. At the end of David’s talk, the guy who wrote Dill, Mike McKerns raised his hand and asked him about it! At the sprints, David and he worked together to get it working in SymPy Live (and coincidentally, he also uses SymPy in another package, mystic). There were some fixes needed for Dill. He also moved Dill out of a larger project (in the spirit of Matthew’s lightning talk), and over to GitHub. Now all they need is a logo (Paul Ivanov suggested a variation on “we can pickle that!”).
In all, it was a fun conference. The best part, as always, was meeting people in person, and talking to them. To conclude, I want to mention two other interesting things that happened.
The first is that Matthew and I talked seriously about how to go about fixing the assumptions in SymPy. I will write to the list about this soon, but the basic idea is to just get in there and hack things together, so that we can get something that works. The work there is started at https://github.com/sympy/sympy/pull/2210, where I am seeing if we can merge the old and new assumptions, so that something assumed in one can be asked in the old one.
The second thing is that Ondrej got a new hat: 
Leave a Comment » | Uncategorized | Permalink
Posted by Aaron Meurer
For https://github.com/sympy/sympy/pull/1969, and previous work at https://github.com/sympy/sympy/pull/1901, we added the ability for the SymPy doctester to run or not run doctests conditionally depending on whether or not required external dependencies are installed. This means that for example we can doctest all the plotting examples without them failing when matplotlib is not installed.
For functions, this is as easy as decorating the function with @doctest_depends, which adds the attribute _doctest_depends_on to the function with a list of what dependencies the doctest depends on. The doctest will then not run the doctest unless those dependencies are installed.
For classes, this is not so easy. Ideally, one could just define _doctest_depends_on as an attribute of the class. However, the issue is that with classes, we have inheritance. But if class A has a docstring with a doctest that depends on some modules, it doesn’t mean that a subclass B of A will have a doctest that does.
Really, what we need to do is to decorate the docstring itself, not the class. Unfortunately, Python does not allow adding attributes to strings
>>> a = "" >>> a.x = 1 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'str' object has no attribute 'x'
So what we have to do is to create a attribute that doesn’t inherit.
I had for some time wanted to give descriptors in Python a try, since they are a cool feature, but also the second most complicated feature in Python (the first is metaclasses). If you don’t know what a descriptor is, I recommend reading this blog post by Guido van Rossum, the creator of Python. It’s the best explanation of the feature there is.
Basically, Python lets attributes define what happens when they are accessed (like a.x). You may already know that objects can define how their attributes are accessed via __getattr__. This is different. With descriptors, the attributes themselves define what happens. This may sound less useful, but in fact, it’s a very core feature of the language.
If you’ve ever wondered how property, classmethod, or staticmethod work in Python, the answer is descriptors. Basically, if you have something like
class A(object):
def f(self):
return 1
f = property(f)
Then A().f magically calls what would normally be A().f(). The way it works is that property defines the __get__ method, which returns f(obj), where obj is the calling object, here A() (remember in Python that the first argument of a method, usually called self, is the object that calls the method).
Descriptors can allow a method to define arbitrary behavior when called, set, or deleted. To make an attribute inaccessible to subclasses, then, you just need to define a descriptor that prevents the attribute from being accessed if the class of the calling object is not the original class. Here is some code:
class nosubclasses(object):
def __init__(self, f, cls):
self.f = f
self.cls = cls
def __get__(self, obj, type=None):
if type == self.cls:
if hasattr(self.f, '__get__'):
return self.f.__get__(obj, type)
return self.f
raise AttributeError
it works like this
In [2]: class MyClass(object):
...: x = 1
...:
In [3]: MyClass.x = nosubclasses(MyClass.x, MyClass)
In [4]: class MySubclass(MyClass):
...: pass
...:
In [5]: MyClass.x
Out[5]: 1
In [6]: MyClass().x
Out[6]: 1
In [80]: MySubclass.x
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-80-2b2f456dd101> in <module>()
----> 1 MySubclass.x
<ipython-input-51-7fe1b5063367> in __get__(self, obj, type)
8 return self.f.__get__(obj, type)
9 return self.f
---> 10 raise AttributeError
AttributeError:
In [81]: MySubclass().x
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-81-93764eeb9948> in <module>()
----> 1 MySubclass().x
<ipython-input-51-7fe1b5063367> in __get__(self, obj, type)
8 return self.f.__get__(obj, type)
9 return self.f
---> 10 raise AttributeError
AttributeError:
Note that by using the third argument to __get__, this works regardless if the attribute is accessed from the class or the object. I have to call __get__ on self.f again if it has it to ensure that the right thing happens if the attribute has other descriptor logic defined (and note that regular methods have descriptor logic defined—that’s how they convert the first argument self to implicitly be the calling object).
One could easily make class decorator that automatically adds the attribute to the class in a non-inheritable way:
def nosubclass_x(args):
def _wrapper(cls):
cls.x = nosubclasses(args, cls)
return cls
return _wrapper
This automatically adds the property x to the decorated class with the value given in the decorator, and it won’t be accessible to subclasses:
In [87]: @nosubclass_x(1)
....: class MyClass(object):
....: pass
....:
In [88]: MyClass().x
Out[88]: 1
In [89]: MySubclass().x
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-89-93764eeb9948> in <module>()
----> 1 MySubclass().x
<ipython-input-51-7fe1b5063367> in __get__(self, obj, type)
8 return self.f.__get__(obj, type)
9 return self.f
---> 10 raise AttributeError
AttributeError:
For SymPy, we can’t use class decorators because we still support Python 2.5, and they were introduced in Python 2.6. The best work around is to just call Class.attribute = nosubclasses(Class.attribute, Class) after the class definition. Unfortunately, you can’t access a class inside its definition like you can with functions, so this has to go at the end.
Name Mangling
After coming up with all this, I remembered that Python already has a pretty standard way to define attributes in such a way that subclasses won’t have access to them. All you have to do is use two underscores before the name, like __x, and it will be name mangled. This means that the name will be renamed to _classname__x outside the class definition. The name will not be inherited by subclasses. There are some subtleties with this, particularly for strange class names (names that are too long, or names that begin with an underscore). I asked about this on StackOverflow. The best answer is that there was a function in the standard library, but it was removed in Python 3. My tests reveal that the behavior is different in CPYthon than in PyPy, so getting it right for every possible class is nontrivial. The descriptor thing should work everywhere, though. On the other hand, getattr(obj, '_' + obj.__class__.__name__ + attributename) will work 99% of the time, and is much easier both to write and to understand than the descriptor.
Leave a Comment » | Uncategorized | Permalink
Posted by Aaron Meurer
In this blog post, when I write 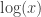

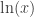
A discussion on a pull request got me thinking about this question: what are the solutions to the complex equation 
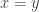




Now, observe that if we apply 
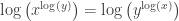
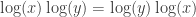
The second question, that of injectivity, is easier to answer than the first, so I’ll address it first. Note that the complex exponential is not one-to-one, because for example 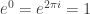
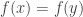

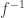
So note that the complex logarithm is not well-defined exactly because the complex exponential is not one-to-one. We of course fix this problem by making it well-defined, i.e., it normally is multivalued, but we pick a single value consistently (i.e., we pick a branch), so that it is well-defined. For the remainder of this blog post, I will assume the standard choice of branch cut for the complex logarithm, i.e., the branch cut is along the negative axis, and we choose the branch where, for 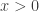

My point here is that we automatically know that the complex logarithm is one-to-one because we know that the complex exponential is well-defined.
So our question boils down to, when does the identity 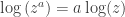
expand_log() or logcombine() when 

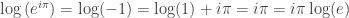
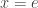
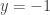
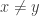
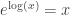


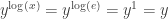
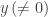





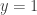
Note that 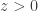
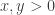
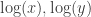

, arbitrary, arbitrary , arbitrary, arbitrary
, arbitrary, arbitraryNow let’s look at some cases where 

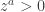
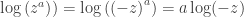
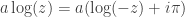
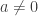
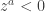



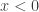

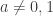
This is as far as I got tonight. WordPress is arbitrarily not rendering that LaTeX for no good reason. That and the very ugly LaTeX images is pissing me off (why wordpress.com hasn't switched to MathJaX yet is beyond me). The next time I get some free time, I am going to seriously consider switching my blog to something hosted on GitHub, probably using the IPython notebook. I welcome any hints people can give me on that, especially concerning migrating pages from this blog.
Here is some work on finding the rest of the solutions: the general definition of 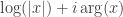

![(-\pi, \pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C+%5Cpi%5D&bg=ffffff&fg=333333&s=0&c=20201002)
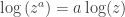
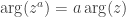

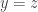
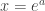
Any comments to this post are welcome. I know you can't preview comments, but if you want to use math, just write it as $latex math$ (like $latex \log(x)$ for
Leave a Comment » | Uncategorized | Permalink
Posted by Aaron Meurer
Usually, when I debug SymPy code with PuDB, I create a script that calls the code, then I put a
import pudb; pudb.set_trace()
in the SymPy library code where I want to start debugging. But this is annoying, first because I have to create the script, and second, because I have to modify the library code, and there’s always the risk of accidentally commiting that. Also, if I want to start debugging somewhere else, I have to edit the files and change it.
Well, I just figured out a better way. First, if you haven’t already, add an alias like this in your bash config file ( As of this pull request, this is no longer necessary. A ~/.profile or ~/.bashrc):alias pudb='python -m pudb.run.pudb script is installed automatically with PuDB.
This will let you run pudb script.py to debug script.py. Next, start PuDB. It doesn’t matter with what. You can just run It occured to me that you can just set the breakpoint when starting isympy with PuDB.touch test.py, and then pudb test.py.
Now, press m, and navigate to where in the library code you want to start debugging. It also helps to use / to search the current file and L to jump to a specific line. When you get to the line where you want to start debugging, press b to set a breakpoint. You can do this in multiple places if you want.
Now, you just have to start isympy from within PuDB. Just run pudb bin/isympy, and immediately press c to jump to the interactive prompt. Now, run whatever code you want to debug. When it gets to the breakpoint, PuDB will open, and you can start debugging. If you type c to continue, it will go back to isympy. But the next time you run something that hits the breakpoint, it will open PuDB again.
This trick works because breakpoints are saved to file (at ~/.config/pudb/saved-breakpoints). In fact, if you want, you can just modify that file in the first step. You can edit your saved breakpoints in the bottom right pane of PuDB.
When you are done and you type Ctrl-D PuDB will pop-up again, asking if you want to quit. That’s because it was running the whole time, underneath isympy. Just press q. Note that you should avoid pressing q while debugging, or else PuDB will quit, and you will be left with just normal isympy (it won’t break at your breakpoints any more). Actually, if you do this, but doing Ctrl-D still opens the PuDB prompt, you can just press “Restart”, and it should start working again. Note that “Restart” will not actually reset isympy: all your saved variables will still be the same, and any changes to the library code will not be reloaded. To do that, you have to completely exit and start over again.
Of course, there is nothing SymPy specific about this trick. As long as you have a script that acts as an entry point to an interactive console for your application, you can use it. If you just use IPython, you can use something like pudb /bin/ipython (replace /bin/ipython with the output of which ipython).
1 Comment | Uncategorized | Permalink
Posted by Aaron Meurer
As readers of this blog may remember, back in 2011, I decided to move to a command-line based editor. For roughly two weeks in December, 2011, I exclusively used Vim, and for the same amount of time in January, 2012, I used exclusively Emacs. I had used a little of each editor in the past, but this was my first time using them to do true editing work. My experiences are chronicled in my blog posts (parts 1, 2, 3, and 7 months later follow up).
To summarize, I decided to use Emacs, as I found it to be much more intuitive, and much more user-friendly. Today, January 1, marks the one-year point of my using Emacs as my sole text editor, with some exceptions (notably, I’m currently writing this blog post in the browser). So I’d like to make some observations:
M-x customize), but on the other hand, Vim’s scripting language is much easier to hack on than Emacs lisp (I still can’t code in Lisp to save my life; it’s a very challenging programming language).
But my point here is that neither has really great defaults. For example, in Emacs, M-space is bound to just-one-space, which is great for programming. What it does is remove all spaces around the cursor, except for one. But to be really useful, it also should include newlines. It doesn’t do this by default. Rather, you have to call it with a negative argument. So to be really useful, you have to add
(defun just-one-space-with-newline () "Call just-one-space with a negative argument" (interactive) (just-one-space -1)) (global-set-key (kbd "M-SPC") 'just-one-space-with-newline)
to your .emacs file.
M-w (Emacs version of copy). And if a feature involves several keystrokes to access, forget about it (for example, rectangular selection, or any features of special modes). If I use a new mode, e.g., for some file type that I rarely edit (like HTML), I might as well not have any of the features, other than the syntax highlighting, because I either don’t know what they are, or even if I know that they should exist (like automatic tag completion for html), I have no idea how to access them.
There’s really something to be said about GUI editors, which give these things to users in a way that they don’t have to memorize anything. Perhaps I should try to use the menu more. Or maybe authors of addons should aim to make features require as little cognitive user interaction as possible (such as the excellent auto-complete-mode I mentioned in part 3).
I mention this because it is one of the things I complained about with Vim, that the keybindings were too hard to memorize. Of course, the difference with Vim is that one has to memorize keybindings to do even the most basic of editing tasks, whereas with Emacs one can always fall back to more natural things like Shift-Arrow Key to select text or Delete to delete the character under the cursor (and yes, I know you can rebind this stuff in Vim; I refer you to the previous bullet point).
ESC and i.emacsclient any more. Ever since I got my new retina MacBook Pro, I don’t need it any more, because with the solid state drive starting Emacs from scratch is instantaneous. I’m glad to get rid of it, because it had some seriously annoying glitches.alias e=emacs to your Bash config file (.profile or .bashrc). It makes life much easier. “emacs” is not an easy word to type, at least on QWERTY keyboards.C-u 4 C-x TAB, actually C-c u 4 C-x TAB, since I did the sensible thing and rebound C-u to clear to the previous newline, and bound universal-argument to C-c u) come to mind).
I feel as if I were to watch someone who has used Emacs for a long time that I would learn a lot of tricks.
imenu. If you know of anything, please let me know. One thing I really liked about Vim was the tag list extension, which did this perfectly (thanks to commenter Scott for pointing it out to me). I’ve been told that Cedet has something like this, but every time I try to install it, I run into some issues that just seem like way too much work (I don’t remember what they are, it won’t compile or something, or maybe it just wants to do just way too much and I can’t figure out how to disable everything except for the parts I want). check-syntax: $(CC) -o nul $(FLAGS) -S $(CHK_SOURCES)
(and if you don’t use a Makefile, start using one now). This is assuming you have CC and FLAGS defined at the top (generally to something like cc and -Wall, respectively). Also, add the following to your .emacs
;; ===== Turn on flymake-mode ==== (add-hook 'c-mode-common-hook 'turn-on-flymake) (defun turn-on-flymake () "Force flymake-mode on. For use in hooks." (interactive) (flymake-mode 1)) (add-hook 'c-mode-common-hook 'flymake-keyboard-shortcuts) (defun flymake-keyboard-shortcuts () "Add keyboard shortcuts for flymake goto next/prev error." (interactive) (local-set-key "\M-n" 'flymake-goto-next-error) (local-set-key "\M-p" 'flymake-goto-prev-error))
The last part adds the useful keyboard shortcuts M-n and M-p to move between errors. Now, errors in your C code will show up automatically as you type. If you use the command line version of emacs like I do, and not the GUI version, you’ll also need to install the flymake-cursor module, which makes the errors show up in the mode line, since otherwise it tries to use mouse popups. You can change the colors using M-x customize-face (search for “flymake”).
Actually, what I really would like is not syntax checking (I rarely make syntax mistakes in LaTeX any more), but rather something that automatically builds the PDF constantly as I type. That way, I can just look over at the PDF as I am writing (I use an external monitor for this. I highly recommend it if you use LaTeX, especially one of those monitors that swivels to portrait mode).
C-a, C-e, etc.), but that only works in Cocoa apps, and it doesn’t include any meta key shortcuts. This lets you use additional shortcuts literally everywhere (don’t worry, it automatically doesn’t use them in the Terminal), including an emulator for C-space and some C-x commands (like C-x C-s to Command-s). It doesn’t work on context sensitive shortcuts, unfortunately, unless the operating system already supports it with another keyboard shortcut (e.g., it can map M-f to Option-right arrow). For example, it can’t enable moving between paragraphs with C-S-{ and C-S-}. If anyone knows how to do that, let me know. (add-hook 'latex-mode-hook 'auto-complete-mode) (add-hook 'LaTeX-mode-hook 'auto-complete-mode) (add-hook 'prog-mode-hook 'auto-complete-mode) ;; etc.
Vim is great for text editing, but not so hot for text writing (unless you always write text perfectly, so that you never need to leave insert mode until you are done typing). Just the simple act of deleting a mistyped word (yes, word, that happens a lot when you are decently fast touch typist) takes several keystrokes, when it should in my opinion only take one (two if you count the meta-key).
Needless to say, I find Emacs to be great for both text editing and text writing.
12 Comments | Uncategorized | Permalink
Posted by Aaron Meurer
The WordPress.com stats helper monkeys prepared a 2012 annual report for this blog.

Here’s an excerpt:
4,329 films were submitted to the 2012 Cannes Film Festival. This blog had 20,000 views in 2012. If each view were a film, this blog would power 5 Film Festivals
1 Comment | Uncategorized | Permalink
Posted by Aaron Meurer
This is what I look like.

