Readers of this blog know that I sometimes like to write about some strange, unexpected, and unusual things in Python that I stumble across. This post is another one of those.
First, look at this
>>> a = [] >>> a.append(a) >>> a [[...]]
What am I doing here? I’m creating a list, a, and I’m adding it to itself. What you end up with is an infinitely nested list. The first interesting thing about this is that Python is smart enough to not explode when printing this list. The following should convince you that a does indeed contain itself.
>>> a[0] is a True >>> a[0] == a True
Now, if you have programmed in C, or a similar language that uses pointers, this should not come as a surprise to you. Lists in Python, like most things, do not actually contain the items inside them. Rather, they contain references (in C terminology, “pointers”) to the items inside them. From this perspective, there is no issue at all with a containing a pointer to itself.
The first thing I wondered when I saw this was just how clever the printer was at noticing that the list was infinitely nested. What if we make the cycle a little more complex?
>>> a = [] >>> b = [] >>> a.append(b) >>> b.append(a) >>> a [[[...]]] >>> b [[[...]]] >>> a[0] is b True >>> b[0] is a True
So it still works. I had thought that maybe repr just catches RuntimeError and falls back to printing ... when the list is nested too deeply, but it turns out that is not true:
>>> a = [] >>> for i in range(10000): ... a = [a] ... >>> a Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: maximum recursion depth exceeded while getting the repr of a list
And by the way, in case you were wondering, it is possible to catch a RuntimeError (using the same a as the previous code block)
>>> try:
... print(a)
... except RuntimeError:
... print("no way")
...
no way
(and you also may notice that this is Python 3. Things behave the same way in Python 2)
Back to infinitely nested lists, we saw that printing works, but there are some things that don’t work.
>>> a[0] == b True >>> a[0] == a Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: maximum recursion depth exceeded in comparison
a[0] is b holds (i.e., they are exactly the same object in memory), so == is able to short-circuit on them. But to test a[0] == a it has to recursively compare the elements of a and a[0]. Since it is infinitely nested, this leads to a recursion error. Now an interesting question: why does this happen? Is it because == on lists uses a depth first search? If it were somehow possible to compare these two objects, would they be equal?
One is reminded of Russel’s paradox, and the reason why in axiomatic set theory, sets are not allowed to contain themselves.
Thinking of this brought me to my final question. Is it possible to make a Python set that contains itself? The answer is obviously no, because set objects can only contain hashable objects, and set is not hashable. But frozenset, set‘s counterpart, is hashable. So can you create a frozenset that contains itself? The same for tuple. The method I used for a above won’t work, because a must be mutable to append it to itself.



 Posted by Aaron Meurer
Posted by Aaron Meurer 
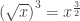 but
but 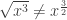 (to see this, replace
(to see this, replace  with -1).
with -1).
